Searching INAUGURAL-RCV1 Collection System using MapReduce Based on Hadoop
Michael Yoseph Ricky
ABSTRACT
Hadoop is an open source application developed by IBM that can be used to perform distributed processing of large data using MapReduce. The purpose of this study was to compare the MapReduce process to search data on Inaugural CORPUS using Python programming language with Multi Nodes Hadoop-based compare to without Hadoop. Based on the experimental results showed that the Mapper and Reducer process for indexing if without Hadoop, the reduce time increased by 20%. In this research, it can be inferred that by leveraging Hadoop to help the process of parallel processing can reduce the processing time and also improve overall performance of the system.
INTRODUCTION
Hadoop is an open source project of the Apache Foundation. It is a framework written in Java originally developed by Doug Cutting who named it after his son’s toy elephant. Hadoop uses Google’s MapReduce and Google File System technologies as its foundation.
It is optimized to handle massive quantities of data which could be structured, unstructured or semi-structured, using commodity hardware, that is, relatively inexpensive computers. This massive parallel processing is done with great performance.
Hadoop replicates its data across multiple computers, so that if one goes down, the data is processed on one of the replicated computers. It is a batch operation handling massive quantities of data, so the response time is not immediate.
Hadoop has two major components:
- The distributed file system component, the main example of which is the Hadoop Distributed File System, though other file systems, such as IBM GPFS-FPO, are supported.
- The MapReduce component, which is a framework for performing calculations on the data in the distributed file system
HDFS was based on a paper Google published about their Google File System, Hadoop’s MapReduce is inspired by a paper Google published on the MapReduce technology. It is designed to process huge datasets for certain kinds of distributable problems using a large number of nodes.
A MapReduce program consists of two types of transformations that can be applied to data any number of times, a map transformation and a reduce transformation. A MapReduce job is an executing MapReduce program that is divided into map tasks that run in parallel with each other and reduce tasks that run in parallel with each other.
MapReduce is a programming model for processing large data sets with a parallel, distributed algorithm on a cluster. It is a way to process large data sets by distributing the work across a large number of nodes. Prior to executing the Mapper function, the master node partitions the input into smaller sub-problems which are then distributed to worker nodes.
in this case, the Hadoop Distributed File System (HDFS) is used and this provides a cluster of commodity-quality data nodes over which the blocks of the files are distributed.
A MapReduce (MR) program comprises a Map procedure or routine that performs extraction, filtering, and sorting and a Reduce procedure that performs a summary operation. The MapReduce infrastructure or framework coordinates and controls the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, providing for redundancy and fault tolerance, and overall management of the whole process.
The model is inspired by Map and Reduce functions commonly used in functional programming, although their purpose in the MapReduce framework is not the same as their original forms. All the same, functional programming breaks down a problem into a set of functions that take inputs and produce outputs.
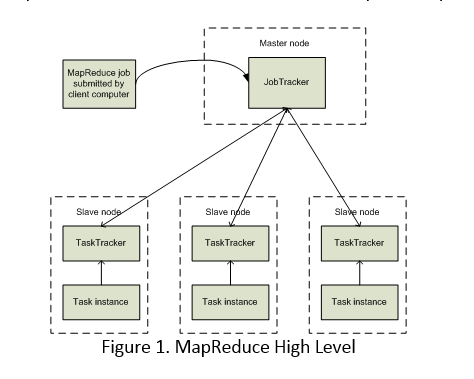
Figure 1. MapReduce High Level
The key contributions of the Hadoop MapReduce framework are not the actual map and reduce functions, but the scalability and fault-tolerance achieved for a variety of applications by optimizing the execution engine once.
There is a single JobTracker for the cluster. Each datanode on the cluster has a TaskTracker and thus there are multiple TaskTrackers, possibly dozen, hundreds, or thousands, depending on the number of nodes in the cluster.
The JobTracker runs on the master node, and a TaskTracker works on each data (or worker) node. Worker nodes may themselves act as master nodes in that they in turn may partition the sub-problem into even smaller sub-problems. In the Reduce step the master node takes the answers from all of the Mapper sub-problems and combines them in such a way as to get the output that solves the problem.
Assume that we have a massively parallel processing database environment. A client program connects to the coordinator node and sends a request to total the number of employees in each job classification. The coordinator node in turn sends that request to each of the nodes. Since for this request there is no inter-data dependencies, each sub-agent is able to process the request against its portion of the table in parallel with all of the other sub-agents.
A Map function reads an input file or generally, a split of a file (in the form of a block or blocks of a file or files) creates a series of key / value pairs, processes each pair, and generates zero or more output key / value pairs.
Map functions do not require any order in the input data and do not provide or require dependencies from one record of data to another. The output of a Map function is written to the local file system as only one copy is needed, it is input to a Reduce function and just a temporary set of data.
The Reduce function is called once for each unique key in sorted order. It then iterates through the values that are associated with that key and outputs zero or more values. The Reduce function works on a set of key / value pairs independently of any other set of key / value pairs and so multiple Reduce functions can be processed in parallel.
The output of a Reduce function is written to HDFS and is thus replicated.
Normally Hadoop MR Applications are written in Java. But there is an API that allows the Map and Reduce functions to be written in any language such as Python.
This is the summary of concept for MapReduce process :
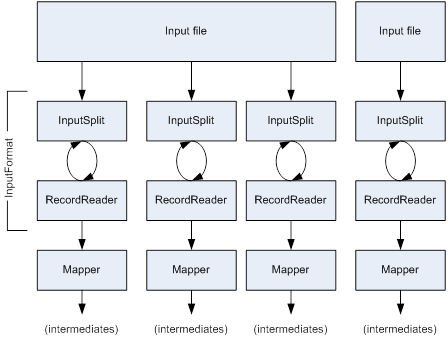
Figure 2. Getting Data to The Mapper
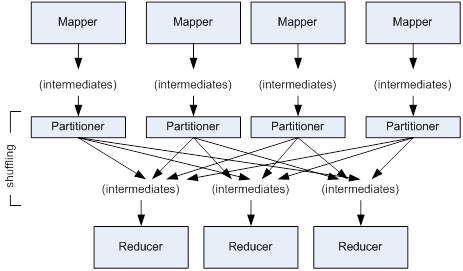
Figure 3. Mapper and Reducer Concept
Finally : Writing the Output
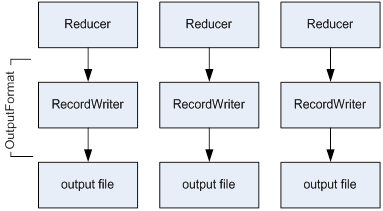
Figure 4. Reducer to Output File
COMPARISON
The MapReduce engine consists of one JobTracker and, for each datanode, a TaskTracker. The client submits a MapReduce job to the JobTracker which in turn pushes the work out to available TaskTrackers. The JobTracker attempts to push the work to the datanode closest to the data, i.e., one that contains a block of the input data.
The JobTracker will generally run on a master node, but on a small cluster or in a pseudo-distributed environment, one simulating a multi-node cluster, the JobTracker may be on the same node as the NameNode.
A TaskTracker runs on a datanode, every datanode. TaskTrackers monitor the running tasks and communicate with the JobTracker.
ANALYZE (EXPERIMENT RESULT)
We’re using a large collection of files containing corpus INAUGURAL. Blocks of these files are stored on multiple data nodes (another computer). The data in one block is not dependent on data in any other block.
A Mapper task gets invoked on each datanode where there is an appropriate block of data. The Mapper function reads the lines of the file, parses out each word, and emits a key / value pair record that contains the word (as the key) and the number of occurrences of that word (which is always 1) as the data. The resulting key / value pairs are sorted on the key value. All records with the same key value are then sent to the same Reducer datanode. There may be multiple sets of key / value pairs handled by a single Reducer datanode. This is the shuffle phase.
Based on previous reseach, figure below show an example for a job with 96 map tasks and 64 reduces. The data show about total tasks, successful tasks, failed tasks, killed tasks.
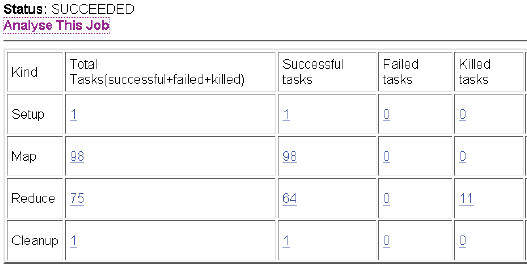
Figure 5. Job Analyze
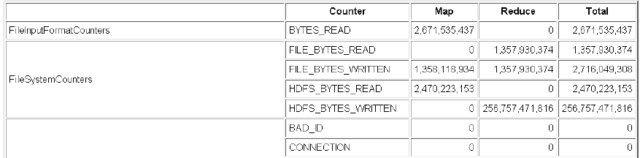
Figure 5. Map and Reduce Analyze
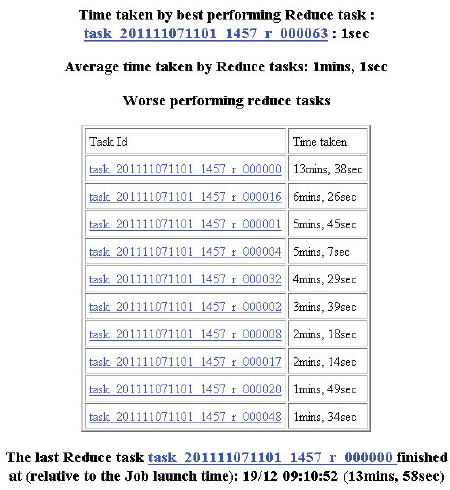
Figure 7. Time Taken by Reduce Task Multi Node Hadoop JobTracker analyze feature for the reduce tasks in a job.
This figure below show stacked chart view of tasks, integrated with machine statistics (CPU and network use) from Ganglia. Data show need 5 minutes to map and shuffle, then 25 minutes to reduces data.

Figure 8. Map, Shufle, Sort, Reduce Time Processing
On each Reducer datanode the Reduce task merges the input records based on the key value. It then iterates through all data values for each key and, in this example, totals those values.
The job of interest consisted of 98 map tasks followed by 64 reduces, run on a cluster with 65 compute nodes. Figure below shows a time-line of task executions faster than MapReduce not using Hadoop. Each horizontal line is the execution interval of a map, shuffle, or reduce task, with tasks ordered from earliest start time (bottom) to latest start time (top). This graphic inform that reduce tasks dominate the execution time of the job. The standard Hadoop JobTracker views indicate this much, but Figure below reveals a curious inverse relation between reduce task duration and shuffle task duration; furthermore, shuffle times are slowest for tasks that started earlier.
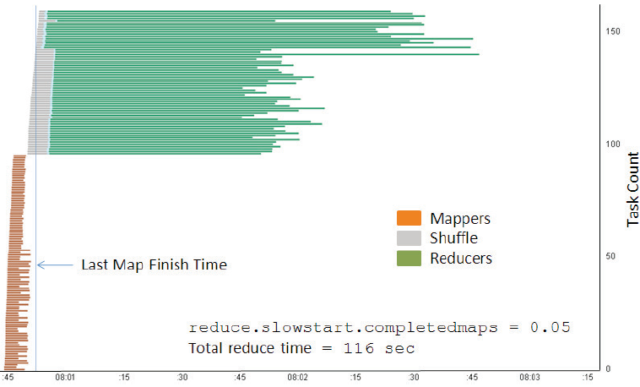
Figure 9. Task durations for one job, using default job parameters. Total reduce time is the elapsed time between start of the first shuffle/reduce task and completion of all tasks using Hadoop Multi Node.
Figure below show the graphic of reduce time without Hadoop and Multi Nodes.
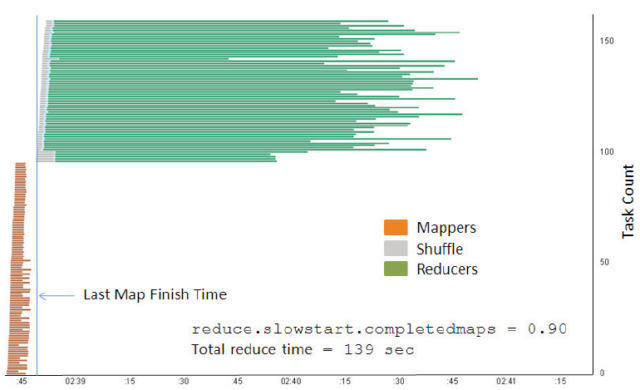
Figure 10. The same job as previous Figure, but the start of shuffle/reduce tasks is delayed until 90% of map tasks are complete. More reduce tasks run slowly, and total reduce time increases by 20%.
In this situation we’re analyze that Hadoop using Multi Nodes and Pararel Processing will reduce the processing time and also increase the performance. But based on Hadoop concept the size of files will affect the speed and performance.
For running create index, we want to make sure OUTPUT folder is not exist. If any index_output or query_output e can delete using syntax : hadoop dfs -rm index_output / hadoop dfs -rm query_output to erase all of files inside folder then hadoop dfs -rm index_output / hadoop dfs -rmdir query_output for delete permanently. Then execute create index :
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-*streaming*.jar -file /home/hduser/createIndexMapper Inaugural.py -mapper /home/hduser/createIndexMapper Inaugural.py -file /home/hduser/createIndexReducer.py -reducer /home/hduser/createIndexReducer.py -input /user/hduser/brown_input/input.txt -output /user/hduser/index_output
After finish indexing, we’re using this syntax : hadoop dfs -cat index_output/part-00000 to view the result, then copy to Linux using hadoop dfs -copyToLocal /user/hduser/index_output/part-00000 part-00000-index_output.txt. The result save in part-00000-index_output.txt
For search in the result, we’re using query :
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-*streaming*.jar -file /home/hduser/queryIndexMapper.py -mapper /home/hduser/queryIndexMapper.py -file /home/hduser/queryIndexReducer.py -reducer /home/hduser/queryIndexReducer.py -input /user/hduser/index_output/part-00000 -output /user/hduser/query_output
DISCUSSION
Searching any CORPUS Collection using MapReduce based on Hadoop Multi Nodes and Pararel Processing proven to reduce the processing time and and can improve the performance of the system as a process to be faster.
Hadoop is aware of the placement of datanodes within the various racks that constitute the cluster. A “rack” in this case should not be thought of as the physical metal structure that the datanode is housed in, but the switch that the datanode is connected to.
Due to the approach that MapReduce takes in solving a problem, the entire job execution time is sensitive to the slowest running task. Hadoop tries to detect any tasks that are running slower than expected.
Hadoop does not try to diagnosis the problem but rather launches an equivalent task. When there are two tasks that are processing the same data, (each block of data resides on several nodes), then one of the two tasks complete (Hadoop does not care which task), Hadoop then kills the remaining task. This approach is called speculative execution.
REFERENCES
[1] GridEngine User’s Guide: http://rc.usf.edu/trac/doc/wiki/gridEngineUsers
[2] GridEngine Hadoop Submission Script: http://rc.usf.edu/trac/doc/wiki/Hadoop
[3] Hadoop Tutorial: http://developer.yahoo.com/hadoop/tutorial/module1.html
[4] Hadoop Streaming: http://hadoop.apache.org/common/docs/r0.15.2/streaming.html
[5] Hadoop API: http://hadoop.apache.org/common/docs/current/api
[6] HDFS Commands Reference: http://hadoop.apache.org/hdfs/docs/current/file_system_shell.htm
[7] http://www.glennklockwood.com/di/hadoop-streaming.php
[8] http://blog.cloudera.com/blog/2013/01/a-guide-to-python-frameworks-for-hadoop/
[9] P. Burkhardt, A profile of Apache Hadoop MapReduce computing efficiency, part II (2010). URL http://www.cloudera.com/blog/2010/12/a-profile-of-hadoop-mapreduce-computing-efficiency-continued/
[10] M. L. Massie, B. N. Chun, D. E. Culler, The ganglia distributed monitoring system: Design, implementation, and experience, Parallel Computing 30 (2004) 817–840
[11] J. Dean, S. Ghemawat, MapReduce: Simplified data processing on large clusters, in: OSDI’04: Sixth Symposium on Operating Systems Design and Implementation, USENIX Association, 2004.
[12] Apache Hadoop project (2015). URL http://hadoop.apache.org/
[13] M. L. Massie, B. N. Chun, D. E. Culler, The ganglia distributed monitoring system: Design, implementation, and experience, Parallel Computing 30 (2004) 817–840.
Comments :