Klasifikasi Kategori Video Berbasis Pembelajaran Mesin
Oleh = Mochammad Haldi Widianto
Pengenalan otomatis alur kerja pembedahan adalah masalah yang belum terselesaikan di antara komunitas intervensi yang dibantu komputer (CAI). Pengenalan fase pembedahan otomatis merupakan dasar dari banyak fungsi di ruang operasi masa depan seperti memantau proses pembedahan dan memberikan bantuan selama pembedahan. Selain itu, ini memenuhi permintaan saat ini untuk mengotomatiskan pengindeksan padat karya dari database video bedah. Di antara studi terbaru untuk pengenalan fase bedah, banyak studi menggunakan triplet bedah (alat yang digunakan, struktur anatomi, dan tindakan bedah) dari setiap bingkai dalam video untuk mewakili setiap kali dalam operasi. Di antara ketiga fitur tersebut, fitur alat yang digunakan sangat penting untuk mendapatkan performa pengenalan fase yang lebih baik seperti yang ditunjukkan di. Untuk mengekstrak fitur ini mengarah ke masalah yang signifikan – deteksi keberadaan alat bedah.
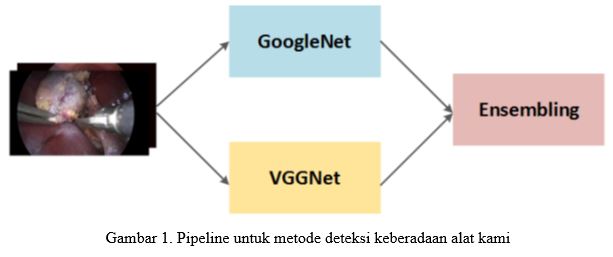
Metode penelitian ini mengikuti dua langkah utama: melatih model CNN – VGGNet dan GoogLeNet, kemudian menggunakan pembelajaran ensemble untuk menggabungkan hasil model untuk mendapatkan hasil akhir. Sebelum memberikan rincian kedua langkah tersebut, kami akan menjelaskan deteksi keberadaan alat bedah sebagai masalah klasifikasi multi-label. Gbr. 1. Saluran pipa untuk metode deteksi keberadaan alat kami. Sisi kiri menunjukkan contoh gambar latih, bagian tengah menunjukkan dua jaringan saraf dalam yang dilatih dari gambar latih, kanan adalah teknik pembelajaran ensembel yang menggabungkan hasil dari kedua model tersebut.
Klasifikasi Multi-label
Klasifikasi kelas jamak tradisional adalah masalah pengklasifikasian instance menjadi salah satu dari lebih dari dua kelas, dan setiap instance hanya dimiliki oleh satu kelas. Berbeda dari klasifikasi multi-kelas, klasifikasi multi-label memungkinkan setiap instance dimiliki oleh satu atau lebih dari satu kelas. Klasifikasi banyak label merupakan generalisasi untuk klasifikasi kelas jamak. Dalam masalah dunia nyata, tugas klasifikasi multi-label ada di mana-mana. Misalnya, dalam kategorisasi teks, setiap dokumen dapat termasuk dalam lebih dari satu topik yang telah ditentukan sebelumnya, seperti olahraga dan kesehatan. Masalah deteksi keberadaan alat bedah juga dapat dipandang sebagai masalah klasifikasi multi-label. Karena setiap gambar yang kami ekstrak sebagai bingkai gambar dari video operasi mungkin berisi satu atau lebih dari satu alat bedah. Dengan demikian, setiap gambar dapat dimiliki oleh satu atau lebih dari satu kelas. Dengan cara ini, kita dapat menggunakan metode klasifikasi multi-label untuk deteksi keberadaan alat bedah. Dua metode umum untuk klasifikasi multi-label adalah transformasi masalah dan adaptasi algoritma. Transformasi masalah menguraikan masalah klasifikasi multi-label menjadi beberapa masalah klasifikasi biner independen. Metode adaptasi algoritme merancang atau mengadaptasi algoritme untuk menyelesaikan klasifikasi multi-label secara langsung. Dalam metode yang diusulkan, kami menggunakan metode transformasi masalah untuk mengubah masalah klasifikasi multi-label menjadi beberapa masalah klasifikasi biner independen. Setiap pengklasifikasi biner adalah untuk mendeteksi jika satu jenis alat digunakan dalam gambar.
VGGNet dan GoogLeNet
VGGNet. VGGNet adalah arsitektur CNN yang dalam dengan 16 lapisan. Berbeda dari arsitektur CNN dalam lainnya, lapisan konvolusional di VGGNet menggunakan filter konvolusi yang sangat kecil (3 3). Dalam proses pelatihan kami, kami menginisialisasi bobot jaringan dengan metode yang disebutkan di. Unit Linear Rektifikasi (ULT) digunakan sebagai fungsi aktivasi VGGNet. Ukuran batch yang digunakan di VGGNet adalah 32. GoogLeNet. GoogLeNet adalah arsitektur jaringan neural konvolusional yang dalam dengan 22 lapisan. GoogLeNet mengintegrasikan beberapa modul awal di dalamnya. Modul awal dapat meningkatkan kedalaman dan lebar jaringan sekaligus menjaga kompleksitas komputasi. GoogLeNet memiliki enam lapisan lebih banyak daripada VGGNet tetapi parameter tiga kali lebih sedikit dibandingkan dengan VGGNet. GoogLeNet memiliki kemampuan untuk pemrosesan multi-skala dan telah mencapai keadaan seni untuk klasifikasi dan deteksi dalam Tantangan Pengenalan Visual Skala Besar ImageNet 2014 (ILSVRC14). Dalam proses pelatihan kami, kami menggunakan Leak ReLU [16] sebagai fungsi aktivasi. Ukuran batch yang digunakan di GoogLeNet adalah 64. Untuk VGGNet dan GoogLeNet, kami menggunakan sigmoid crossentropy sebagai fungsi kerugian dan menggunakan normalisasi batch setelah lapisan konvolusional
Model Ensembling
Ansambel terdiri dari sekumpulan pengklasifikasi yang terlatih secara independen yang prediksinya digabungkan sebagai prediksi akhir saat mengklasifikasikan instance baru. Banyak studi penelitian telah menunjukkan bahwa kombinasi yang baik dari prediksi beberapa pengklasifikasi dapat menghasilkan pengklasifikasi yang lebih baik. Kami menggunakan ansambel dalam metode kami karena tiga alasan berikut: Pertama, menurut teori pembelajaran ansambel, menjanjikan untuk mendapatkan kinerja klasifikasi yang lebih baik dari ansambel pengklasifikasi yang dilatih secara individual. Kedua, proses training deep neural network cenderung overfitting dataset training meskipun beberapa teknik untuk menghindari overfittings seperti early stopping dan dropout digunakan dalam proses training atau arsitektur jaringan. Ketiga, kumpulan data yang disediakan oleh tantangan selalu memiliki varian yang lebih besar. Jadi, meskipun kami mendapatkan kinerja yang baik pada kumpulan data validasi, kami tidak dapat menjamin kinerja yang sama pada kumpulan data pengujian. Dalam metode yang diusulkan, kami menggunakan rata-rata model untuk menggabungkan prediksi dari semua GoogLeNet dan VGGNet terlatih bersama-sama untuk mendapatkan prediksi akhir. Sederhananya, kami memiliki probabilitas prediksi untuk setiap instance dari masing-masing model yang dilatih dan kami menghitung rata-rata probabilitas sebagai probabilitas akhir untuk instance tersebut.
Deskripsi Data dan Augmentasi
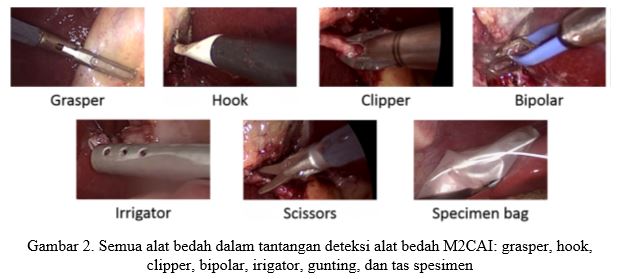
Dataset dari deteksi keberadaan alat bedah M2CAI ini berisi 15 video prosedur kolesistektomi laparoskopi dari Rumah Sakit Universitas Strasbourg / IRCAD (Strasbourg, Prancis). Dataset dibagi menjadi dua bagian: subset pelatihan (berisi sepuluh video) dan subset pengujian (5 video) oleh penyelenggara tantangan. Dari 15 video tersebut, terdapat tujuh jenis alat bedah secara keseluruhan seperti yang ditunjukkan pada Gambar 2: grasper, hook, clipper, bipolar, irigator, gunting dan specimen bag. Kami memberi tahu tujuh alat dari T1 ke T7 secara singkat. Dari angka-angka tersebut kami menemukan bahwa kumpulan data tidak seimbang, yang membuatnya lebih sulit untuk ditangani oleh model. Gbr. 2. Semua alat bedah dalam tantangan deteksi alat bedah M2CAI: grasper, hook, clipper, bipolar, irigator, gunting, dan tas spesimen.
Preprocessing dan Augmentasi Data
Pemrosesan Awal Data. Kami mengekstrak gambar yang memiliki label kebenaran dasar dari sepuluh video pelatihan dan mengubah ukurannya menjadi ukuran yang sama (224 x 224) karena video tersebut memiliki dimensi yang berbeda. Kami menggunakan data dari sepuluh video pelatihan sebagai set pelatihan dan validasi. Untuk lima video pengujian, kami mengekstrak gambar seperti yang diharuskan oleh tantangan sebagai set pengujian. Kami juga mengubah ukurannya menjadi 224 x 224. Tantangan Deteksi Kehadiran Alat Bedah 1M2CAI 2016:.
Metode Rata-rata AP
Metrik evaluasi adalah ketepatan akurasi rata-rata. Augmentasi Data. Kami memperkenalkan tiga jenis metode augmentasi data: membalik horizontal, membalik vertikal, dan rotasi. Dalam implementasinya, kami tidak membuat kumpulan data yang ditambah sebelum pelatihan. Sebagai gantinya, kami menambahkan setiap gambar secara dinamis melalui masing-masing dari tiga metode augmentasi di setiap epoch proses pelatihan. Untuk setiap gambar dalam periode pelatihan tertentu, probabilitas 0,5 untuk dibalik secara horizontal. Ini juga memiliki kemungkinan 0,5 untuk dua augmentasi lainnya. Ketiga metode augmentasi dilakukan secara independen. Karenanya, kami menambah kumpulan data pelatihan kami secara dinamis untuk melatih model dengan lebih baik. Kami tidak menambah set validasi atau set pengujian kami.
Kami menggunakan ansambel prediksi akhir dari sepuluh model pada set pengujian sebagai pengajuan akhir untuk tantangan deteksi kehadiran alat bedah M2CAI. Nilai rata-rata ketepatan akurasi (MAP) dari semua peserta tercantum dalam Tabel. Metode yang diusulkan memiliki peta yang lebih baik daripada metode lainnya. Metode oleh Sahu et al. memiliki kinerja terbaik kedua dengan memperkenalkan informasi temporal untuk membantu klasifikasi. Ini menunjukkan bahwa model kami memiliki kinerja yang sangat baik bahkan tanpa mempertimbangkan informasi temporal. menunjukkan peta untuk setiap jenis alat bedah. Metode kami masih dipengaruhi oleh ketidakseimbangan kumpulan data. Upaya lebih lanjut harus dilakukan untuk menangani ketidakseimbangan data..
Referensi :
Sheng Wang, Ashwin Raju, Junzhou Huang, “DEEP LEARNING BASED MULTI-LABEL CLASSIFICATION FOR SURGICAL TOOL PRESENCE DETECTION IN LAPAROSCOPIC VIDEOS,” The University of Texas at Arlington, Dept. of Computer Science and Engineering, Arlington, TX, USA, 2017
Comments :