Anotasi Semi-Otomatis Skalabel untuk Pelacakan Orang Multi-Kamera
Oleh = Mochammad Haldi Widianto
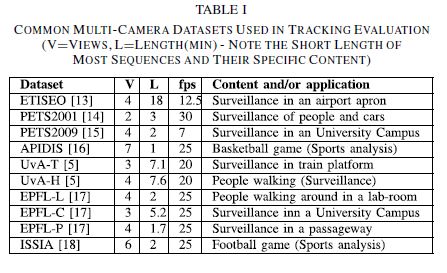
Salah satu masalah terpenting dalam visi komputer adalah masalah pelacakan objek visual. Pelacakan visual telah dipelajari selama bertahun-tahun, yang menghasilkan literatur ilmiah yang kaya dan berlimpah, diringkas dengan baik dalam survei terbaru. Pelacak multi-tampilan yang ada biasanya dievaluasi pada konten yang relatif sederhana seperti orang yang berjalan atau berdiri tanpa kehadiran furnitur dan untuk alasan praktis pada urutan pendek, misalnya. Untuk aplikasi kehidupan nyata, ada risiko yang cukup besar bahwa solusi yang ada disetel secara berlebihan ke kumpulan data tertentu. Oleh karena itu, pengujian pada kumpulan data video yang semakin banyak sangat penting untuk mengeksplorasi kapan dan seberapa sering pelacak gagal dalam berbagai kondisi. Untuk visi komputer kamera tunggal, kebenaran dasar berlimpah, mengingat perkembangan terkini alat semi-otomatis yang mengeksploitasi Amazon Mechanical Turk (MTurk), mis. PPN. Sebagai perbandingan, untuk analisis video multi-kamera, kebenaran dasar jauh lebih langka. Tabel I mencantumkan kumpulan data multi-kamera paling populer (dengan tampilan tumpang tindih) yang telah digunakan untuk mengevaluasi pelacak. Sebagian besar set data ini dianotasi secara manual menggunakan alat seperti ViPER. Kebenaran dasar yang tersedia ini sangat berguna, tetapi tidak selalu mewakili kondisi eksperimental yang diinginkan untuk penelitian baru, yang mungkin memerlukan resolusi kamera atau kecepatan bingkai yang berbeda, nomor atau jenis kamera yang berbeda dengan sudut pandang berbeda, kondisi lingkungan berbeda, dll. Apa itu dibutuhkan prosedur yang lebih efisien untuk menghasilkan anotasi, atau penggantinya, dalam kumpulan data baru.
Pembuatan referensi untuk evaluasi sangat penting untuk menilai dan meningkatkan kinerja detektor dan pelacak. Basis data kebenaran dasar yang komprehensif sebagian besar dibuat menggunakan anotasi manual padat karya dari video, yang biasanya membatasi basis data menjadi urutan pendek; salah satu pendekatannya adalah dengan mengandalkan crowd-sourcing, seperti yang telah dilakukan untuk penjelasan rinci tentang orang-orang dalam gambar tunggal dan untuk menggambarkan kotak pembatas dalam video. Namun, pendekatan ini pun masih padat karya dan membutuhkan banyak pelatihan dan validasi untuk memastikan kualitas hasil. Untuk menciptakan kebenaran dasar dalam video multi-kamera, sejauh ini hanya anotator manual yang telah dilaporkan. Salah satu solusinya adalah dengan menerapkan sistem kamera tunggal seperti VATIC untuk setiap tampilan secara independen. Namun, pendekatan semi-otomatis seperti itu pun sangat padat karya. Misalnya, Vondrick et al. melaporkan bahwa membuat anotasi 24 jam video membutuhkan waktu sekitar 8 bulan manusia dari waktu anotasi manual; aplikasi yang dilaporkan adalah pelacakan mobil dari banyak mobil dalam satu tampilan. Selain itu, strategi yang menerapkan sistem semi-otomatis untuk anotasi tampilan tunggal ini membuka pertanyaan tentang cara menggabungkan hasil dari beberapa kamera. Bagaimanapun, kami tidak mengetahui metode apa pun untuk menghasilkan hasil pelacakan referensi untuk pelacakan multi-kamera dengan cara semi-otomatis dan efisien.
Ide menggabungkan hasil dari beberapa pelacak untuk meningkatkan kinerja pelacakan. Secara khusus, Zhong et al. mendekati pelacakan objek tampilan tunggal sebagai masalah pembelajaran yang diawasi dengan lemah, di mana keluaran dari beberapa pelacak diperlakukan sebagai label berisik. Kerangka kerja probabilistik untuk integrasi optimal labeller yang diusulkan digunakan untuk bersama-sama menyimpulkan posisi objek dan akurasi setiap pelacak. Heuristik yang mengukur kesepakatan di antara pelacak digunakan untuk pemilihan data pelatihan dan untuk memperbarui model pelacak. Dengan mengambil sampel tidak hanya status target tetapi juga pelacak yang terlibat dalam penghitungannya, metode yang diusulkan menghasilkan proposal untuk kombinasi terbaik dari komponen pelacak. Posisi target kemudian diperkirakan dari kombinasi yang dipilih. pendekatan berbasis ketidaksepakatan menghitung bobot kombinasi linier dari peta probabilitas yang diperoleh dari beberapa pelacak. Pendekatan berbasis ketidaksepakatan seperti itu juga disajikan dalam. Untuk menemukan kotak pembatas target yang optimal, ukuran tarikan dalam ruang 4 dimensi (posisi dan ukuran) antara kotak pembatas dari pelacak kandidat fusi dan pelacak dimaksimalkan. Sebuah heuristik untuk penghapusan pelacak buruk diusulkan untuk meningkatkan perkiraan kotak pembatas. Peneliti lain telah mengusulkan kerangka kerja ensembel pelacak simbiosis untuk mempelajari kombinasi hasil yang optimal dari beberapa pelacak. Kombinasi ini didasarkan pada perkiraan konsistensi sementara pelacak individu dan korelasi pelacak berpasangan. Dalam bentuk lain dari pelacakan konsensus, model Markov tersembunyi faktorial mempelajari lintasan target yang tidak diketahui dan keandalan setiap pelacak.
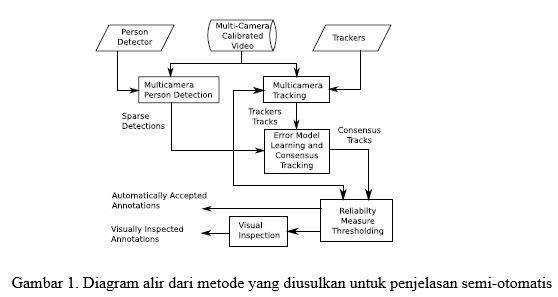
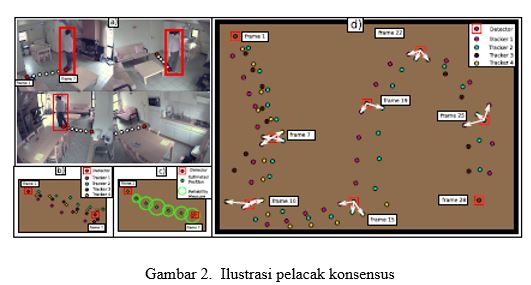
setiap anotasi di trek Gambar 2; yang terakhir adalah ukuran tingkat kesepakatan antara keluaran dari berbagai pelacak. Ukuran ini dibobotkan oleh model kesalahan posisi dari setiap pelacak, yang dipelajari secara otomatis pada langkah sebelumnya. Dengan membatasi ukuran ini, kami membagi anotasi konsensus sesuai dengan keandalannya. Anotasi yang dianggap dapat diandalkan diterima secara otomatis. Anotasi yang dianggap tidak dapat diandalkan tunduk pada prosedur manual, di mana manusia memutuskan untuk menerima / menolak frame beranotasi. Keputusan ini didasarkan pada inspeksi visual yang efisien, yang diterapkan pada anotasi sampel yang strategis. Untuk mengilustrasikan konsep di balik pelacak konsensus, kita akan menggunakan contoh mainan dari Gambar. 2a-c, memperlihatkan seseorang berjalan di antara dua lokasi, diamati dari empat pemandangan. Perhatikan bahwa meskipun contoh mainan itu sendiri adalah kasus yang mudah untuk pelacak canggih, ini menjelaskan ide-ide dasarnya. Ide-ide ini digeneralisasikan ke skenario pelacakan yang lebih kompleks. Meskipun sederhana secara konseptual, pendekatan penelusuran konsensus menghadirkan sejumlah masalah. Pertama-tama, pelacak perlu diinisialisasi sebelum pelacakan dapat dimulai dan setelah terjadi kerugian pelacakan, tetapi tidak semua pelacak yang tersedia menerapkan metode inisialisasi. Selain itu, banyak pelacak yang didasarkan pada prinsip dasar yang serupa (misalnya, segmentasi latar depan, analisis warna …) dan karena itu cenderung gagal dalam keadaan yang serupa. Dengan demikian, konsensus suara mayoritas sederhana atau rata-rata keluaran mereka mungkin berakhir pada perkiraan posisi yang salah.
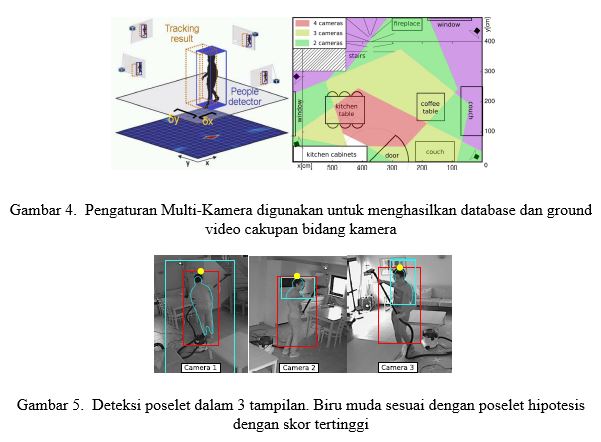
Untuk menghasilkan urutan awal dari referensi yang paling andal untuk posisi orang, kami menyetel “deteksi ambang batas skor ”λd mengikuti prosedur yang diusulkan dalam menggunakan kurva KOP yang tersedia. Kami menetapkan parameter ini untuk sekitar 5% dari positif palsu per gambar. Ini menghasilkan λd = 2.8. Perhatikan bahwa kami belum melatih ulang detektor dengan gambar yang digunakan dalam eksperimen kami, melainkan menggunakan model empiris yang sudah ada yang disediakan oleh penulis. Pilihan ini berarti pengguna tidak perlu menggunakan prosedur anotasi yang kami usulkan untuk menghabiskan waktu tambahan untuk melatih detektor orang. Untuk mendapatkan posisi bidang tanah q (i) dari kotak pembatas gambar Q (i) n, kita mengandalkan triangulasi geometri multi-view [53]. Kami berasumsi bahwa bagian atas kepala seseorang terletak di koordinat tengah-atas dari kotak pembatas poselet, seperti yang diilustrasikan pada Gambar 5. Dengan titik ini sebagai referensi, kami memperkirakan koordinat dunia nyata (X, Y, Z) dari bagian atas kepala saat Deteksi poselet gambar tersedia dalam setidaknya 2 tampilan. Perhatikan bahwa kami hanya menyimpan koordinat bidang tanah (X, Y), karena kami memfokuskan studi kami pada pelacakan posisi orang dalam 2D. Untuk memastikan referensi yang andal, kami hanya menyimpan deteksi bidang tanah di mana kesalahan dalam proyeksi ulang kepala orang di bawah ambang λt. Kami menggunakan nilai λt = 50pi xels untuk sekuens video yang digunakan dalam makalah ini, yang kami temukan secara eksperimental. Untuk urutan video lain, nilai yang berbeda bisa lebih baik, yang terutama bergantung pada konfigurasi multi-kamera.
Studi ini mengusulkan metode baru untuk pembuatan anotasi posisi semi-otomatis dalam sistem multi-kamera yang dikalibrasi, yang ditargetkan untuk urutan video panjang. Kontribusi utama dari makalah ini adalah prosedur baru untuk memadukan hasil dari beberapa pelacak yang melibatkan perkiraan statistik kesalahan pelacak individu (dan mode kegagalan bersama mereka) dengan membandingkan keluaran mereka dengan detektor orang yang dapat diandalkan. Pelacak konsensus berdasarkan statistik ini menghasilkan pelacakan yang lebih akurat daripada rata-rata keluaran pelacak, dan keluaran individu pelacak. Hal baru lainnya adalah kami mengusulkan metode untuk memperkirakan waktu yang dibutuhkan untuk bagian manual dari prosedur yang diusulkan. Kami juga memperkirakan ketepatan kumpulan data beranotasi semi-otomatis yang dihasilkan, dengan nilai akurasi yang diinginkan. Studi ini mendemonstrasikan performa metode kami dengan eksperimen pada set data video multi-kamera berdurasi sekitar 6 jam, yang menunjukkan skalabilitas dalam anotasi semi-otomatis untuk urutan multi-kamera yang panjang untuk pertama kalinya. Hal ini membawa kita pada kontribusi akhir dari makalah ini: data beranotasi itu sendiri, yang tersedia dalam dua versi: versi pertama dihasilkan dari prosedur yang diusulkan; yang kedua dari pemeriksaan menyeluruh untuk menciptakan kebenaran dasar. Karena kumpulan data multi-kamera beranotasi dengan panjang seperti itu belum dilaporkan dalam literatur, kami berharap urutan beranotasi ini akan berguna bagi komunitas peneliti.
Referensi :
- Jorge Niño-Castañeda, Andrés Frías-Velázquez, Nyan Bo Bo, Maarten Slembrouck, Junzhi Guan, Glen Debard, Bart Vanrumste, Tinne Tuytelaars, and Wilfried Philips, “Scalable Semi-Automatic Annotation for Multi-Camera Person Tracking ,” IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 5, MAY 2016, Colombia
Comments :