Deteksi dan Klasifikasi Objek berbasis YOLO dalam rekaman video
Oleh = Mochammad Haldi Widianto
Manusia melihat gambar dan langsung memproses objek di dalamnya dan menentukan lokasinya karena neuron otak yang saling terkait. Otak manusia sangat akurat dalam melakukan tugas-tugas kompleks seperti mengidentifikasi objek dengan atribut serupa, dalam waktu yang sangat singkat. Sama seperti interpretasi manusia, dunia saat ini membutuhkan algoritma yang cepat dan akurat untuk mengklasifikasikan dan mendeteksi berbagai objek untuk berbagai aplikasi. Aplikasi ini meliputi deteksi pejalan kaki, penghitungan kendaraan, pelacakan gerak, deteksi sel kanker dan banyak lagi. Untuk sistem visual manusia, persepsi informasi visual dengan mudah terlihat. Dalam kecerdasan buatan, kita menghadapi sejumlah besar informasi visual dan sedikit teknik yang berguna untuk memproses, memahami, dan mengklasifikasikannya. Deteksi objek dan algoritma pelacakan dijelaskan dengan mengekstraksi fitur gambar dan video untuk aplikasi keamanan. Fitur diekstraksi menggunakan jaringan neural konvolusional dan pembelajaran mendalam. Pengklasifikasi digunakan untuk klasifikasi dan penghitungan gambar. Proses klasifikasi objek dan alur kerja pendeteksian bertujuan untuk mengklasifikasikan objek berdasarkan fitur dan atributnya. Seiring berlalunya waktu, banyak pendekatan telah digabungkan dari waktu ke waktu untuk mendapatkan hasil yang lebih baik. Pendekatan deteksi objek telah berkembang dari metode berbasis jendela geser ke kerangka kerja deteksi bidikan tunggal. Jaringan Neural Konvolusional (CNN), khususnya, memiliki banyak aplikasi seperti pengenalan wajah, karena mencapai penurunan tingkat kesalahan yang besar tetapi dengan mengorbankan kecepatan dan waktu komputasi. Jaringan Konvolusional Berbasis Wilayah (R-CNN) menggunakan proses Pencarian Selektif untuk mendeteksi objek. Turunan RCNN, Fast R-CNN dan, Faster R-CNN memperbaiki sifat lambat CNN dan R-CNN dengan membuat proses pelatihan ujung ke ujung.
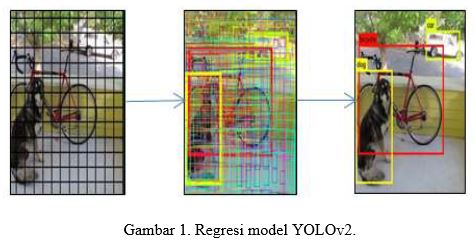
YOLOv2 (You Only Look Once versi 2) adalah teknik deteksi objek yang proses pendeteksiannya dianggap sebagai masalah backsliding tunggal yang mengambil gambar input dan menghasilkan tingkat kepercayaan dari setiap objek pada gambar. Ini adalah turunan dari algoritma YOLO primitif. Gambar 1 menggambarkan model regresi dimana gambar yang diberikan sebagai input dibagi menjadi beberapa grid, diikuti dengan pembentukan kotak pembatas pada semua objek dan terakhir deteksi objek sesuai kebutuhan. Algoritme pendeteksian YOLOv2 menemukan asal-usulnya dari kerangka pembelajaran mendalam sumber terbuka yang dikenal sebagai Darknet. Darknet didasarkan pada arsitektur GoogLeNet. YOLOv2 sangat cepat dan membuat kesalahan latar belakang lebih sedikit daripada pendekatan R-CNN tradisional. YOLOv2 membagi setiap gambar menjadi beberapa kotak kisi dan setiap kotak kisi memprediksi kotak batas tertentu dan tingkat kepercayaan terkait. Tingkat kepercayaan mencerminkan ketepatan pelokalan objek, apa pun kelasnya. Sebagian besar kotak kisi dan kotak pembatas dihapus menghitung nilai ambang batas yang lebih sedikit, meninggalkan kelas objek tertentu, yang dilatih untuk dideteksi. Pekerjaan yang diusulkan terutama dimotivasi oleh dua masalah utama yang ada dalam algoritme CNN tradisional. Ini adalah tingkat akurasi yang rendah dan kecepatan komputasi yang lambat karena tidak adanya GPU. Gambar 2 menunjukkan grafik kecepatan versus akurasi dari berbagai algoritma deteksi. Makalah ini, berfokus pada kerja dan implementasi algoritma deteksi YOLOv2 oleh sistem deteksi YOLO9000 dan menjalankannya pada rekaman video, yang akan memprediksi kotak pembatas beserta anotasi pada objek. Algoritma ini diimplementasikan terutama menggunakan pustaka OpenCV.

Bagian ini menjelaskan keseluruhan persyaratan desain dan implementasi model YOLO pada gambar masukan. Bagian ini juga menjelaskan bagaimana model secara efisien dan akurat mendeteksi dan mengklasifikasikan objek dengan mengimplementasikan Anchor Boxes dan lingkungan CUDA.
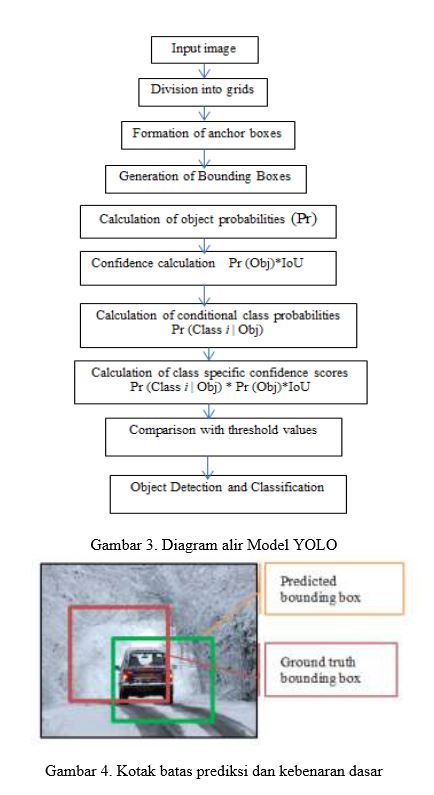
Gambar 3 menunjukkan diagram alir model YOLO. Model YOLO mengikuti metode aliran tertentu untuk menganalisis dan mendeteksi objek dengan cepat. Pertama, ini mengikuti model regresi di mana ia mengambil input dan memperoleh probabilitas kelas. Kedua, menghitung skor keyakinan khusus kelas. Terakhir, membandingkan skor kepercayaan dengan nilai ambang batas yang telah ditentukan untuk mendeteksi dan mengklasifikasikan objek. Jika skor keyakinan kurang dari nilai ambang batas, algoritme tidak akan mendeteksi objek tertentu tersebut.
Intersection over Union adalah metrik pengukuran yang digunakan untuk menghitung ketepatan detektor dan pengklasifikasi objek pada set data tertentu. Ini terdiri dari dua metrik evaluasi. kotak. Ini membantu dalam menentukan kotak pembatas terdekat untuk objek tertentu.
Model YOLOv2 membagi gambar input menjadi sel grid N × N. Setiap sel kisi memiliki tugas untuk melokalkan objek jika titik tengah objek tersebut berada dalam sel kisi. Tetapi pendekatan sel grid hanya dapat memprediksi satu objek pada satu waktu. Jika titik tengah dua objek bertepatan satu sama lain, algoritme pendeteksian hanya akan memilih salah satu objek.
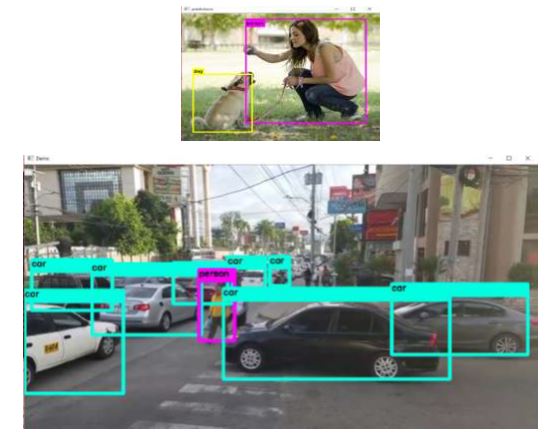
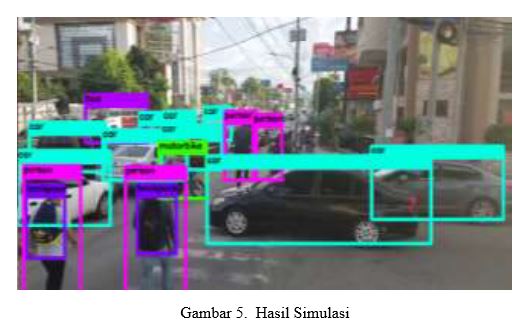
Agar algoritme YOLOv2 dapat mengeksekusi dan mendeteksi objek, kami telah menggunakan Microsoft Visual C ++ 2017 untuk membangun file .exe. Kami telah menerapkan anak timbangan yolo9000 terlatih dan konfigurasinya. Sistem kami terdiri dari GPU berkemampuan NVIDIA GEFORCE 940 MX. Gambar di bagian ini menggambarkan kinerja model YOLOv2 pada gambar diam dan rekaman video. Gambar 6 dan Gambar 8 menggambarkan deteksi dan pelabelan objek dalam satu gambar. Pada Gambar di atas, ada dua objek dan mendeteksi mereka dengan tingkat kepercayaan yang komprehensif, seperti yang ditunjukkan pada Gambar di atas. Waktu untuk menghitung algoritma deteksi untuk gambar ini sudah dekat. Semakin meningkatkan jumlah objek dalam gambar, kecepatan eksekusi tidak menurun. Model YOLOv2 mendeteksi sebagian besar objek dengan tingkat kepercayaan yang mahir. Hal ini digambarkan pada Gambar di atas, yang memiliki jumlah objek lebih banyak dibandingkan dengan Gambar. Di atas. Waktu eksekusi untuk gambar ini mendekati 0,5 detik. Saat kita berpindah dari gambar ke input video, skenario berubah total. Objek dalam video sekarang akan terus berubah koordinatnya. Algoritma YOLOv2 di sini terus menerus mendeteksi dan melabeli objek dengan tingkat kepercayaan yang tinggi. Kami telah mengambil beberapa gambar diam dari rekaman video yang kami berikan sebagai input. Gambar 13 di atas menggambarkan variasi jumlah objek dalam video. Karena jumlah objek terus meningkat, hal itu tidak memengaruhi deteksi objek tetangga lainnya. Ini memberikan kinerja deteksi dan klasifikasi yang baik..
Dalam studi ini, diperkenalkan model YOLOv2 dan YOLO9000, sistem deteksi real-time untuk mendeteksi dan mengklasifikasikan objek dalam rekaman video. YOLOv2 gesit dan efisien dalam mendeteksi dan mengklasifikasikan objek. Kecepatan dan akurasi masing-masing dicapai dengan bantuan fungsionalitas GPU dan teknik Anchor Box. Selain itu, YOLOv2 dapat mendeteksi pergerakan objek dalam rekaman video dengan akurasi yang mahir. YOLO9000 adalah kerangka kerja waktu nyata yang mampu mengoptimalkan deteksi dan klasifikasi serta menjembatani kesenjangan di antara keduanya. Model YOLOv2 dan sistem deteksi YOLO 9000 secara kolektif dapat mendeteksi dan mengklasifikasikan objek yang bervariasi dari beberapa contoh objek tunggal hingga beberapa contoh beberapa objek.
Referensi :
Arka Prava Jana, Abhiraj Biswas, Mohana, “YOLO based Detection and Classification of Objects in video records,” 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT-2018), MAY 18th & 19th 2018, Bengaluru, India
Comments :